
TL;DR: If you work in media generation, you know the frustration: an idea pops into your mind, you type a prompt, maybe provide a reference image, and want to see the result immediately – while the idea is still alive. But existing video generation APIs break the loop. You wait minutes for clips, and each costs enough to make your wallet wince. FastVideo’s real-time inference stack fixes this problem.
The FastVideo team has built a highly optimized production-grade 1080p text-image-to-audio-video (TI2AV) pipeline that achieves real-time generation. We turn LTX-2.3, an open-source TI2AV model, into a single-GPU speed machine for interactive media generation: it generates 5-second 1080p videos with audio with an end-to-end latency of ~4.5 seconds on a single B200 GPU. We believe this is a major turning point in making high-quality video generation fast enough to feel interactive. Our optimizations will be upstreamed to FastVideo’s main branch in the near future.
If you have the need for speed (and quality), try our demo for free.
The biggest bottleneck in video generation is no longer just model quality. It is the broken feedback loop during creative iteration. As a creator, designer, or builder working with AI video models, you don’t want just a single generated video, you want to have the ability to explore with multiple generations. You want to try multiple ideas, change the framing, swap the style, adjust the motion, add a reference image, rerun, and keep going until perfection. This is how real creative work happens. But when each attempt takes minutes and hits your budget, the creation loop just collapses – a tool is not effective if it becomes slower than your imagination! For example, generating an 8-second video with Google’s Veo-3 Fast takes about 55 seconds. While Veo is an impressive model, it is still too slow and expensive for the rapid iteration that modern media-generation workflows demand. If generation is slower than the pace of ideation, then frequent iteration becomes impractical.
Recent research efforts have greatly reduced video generation latency, but most of these systems are still limited to 480p, or at best 720p, and often do not produce audio. 1080p is where things get serious. It is where outputs become much more usable for storytelling, content creation, and real products – but it is also where the systems challenges become much harder. The spatial workload grows dramatically, attention becomes more expensive, memory pressure rises, and every inefficiency in the stack gets amplified. Achieving interactive latency at full-HD resolution requires deep optimizations of model execution, scheduling, and kernel efficiency.
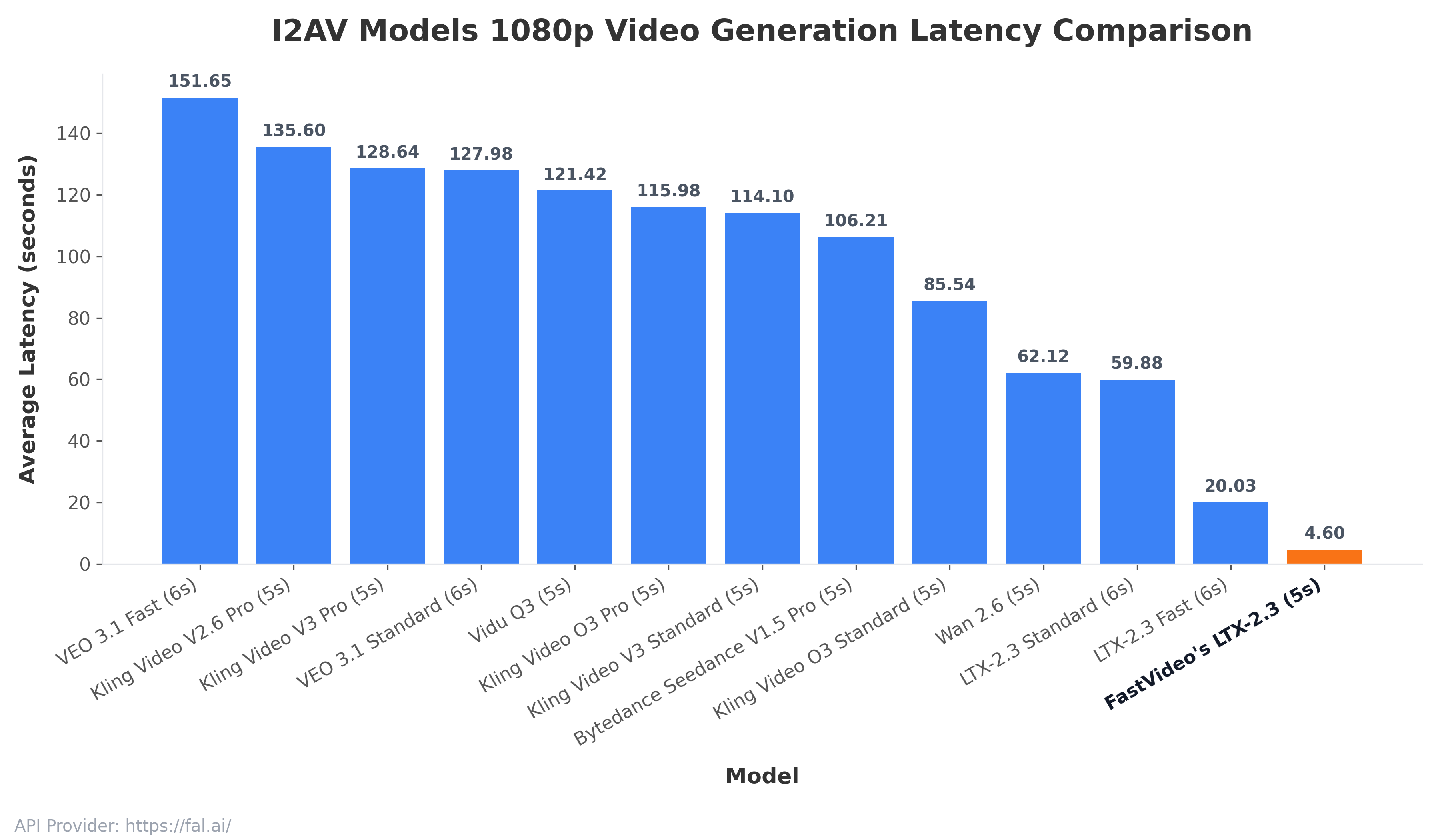
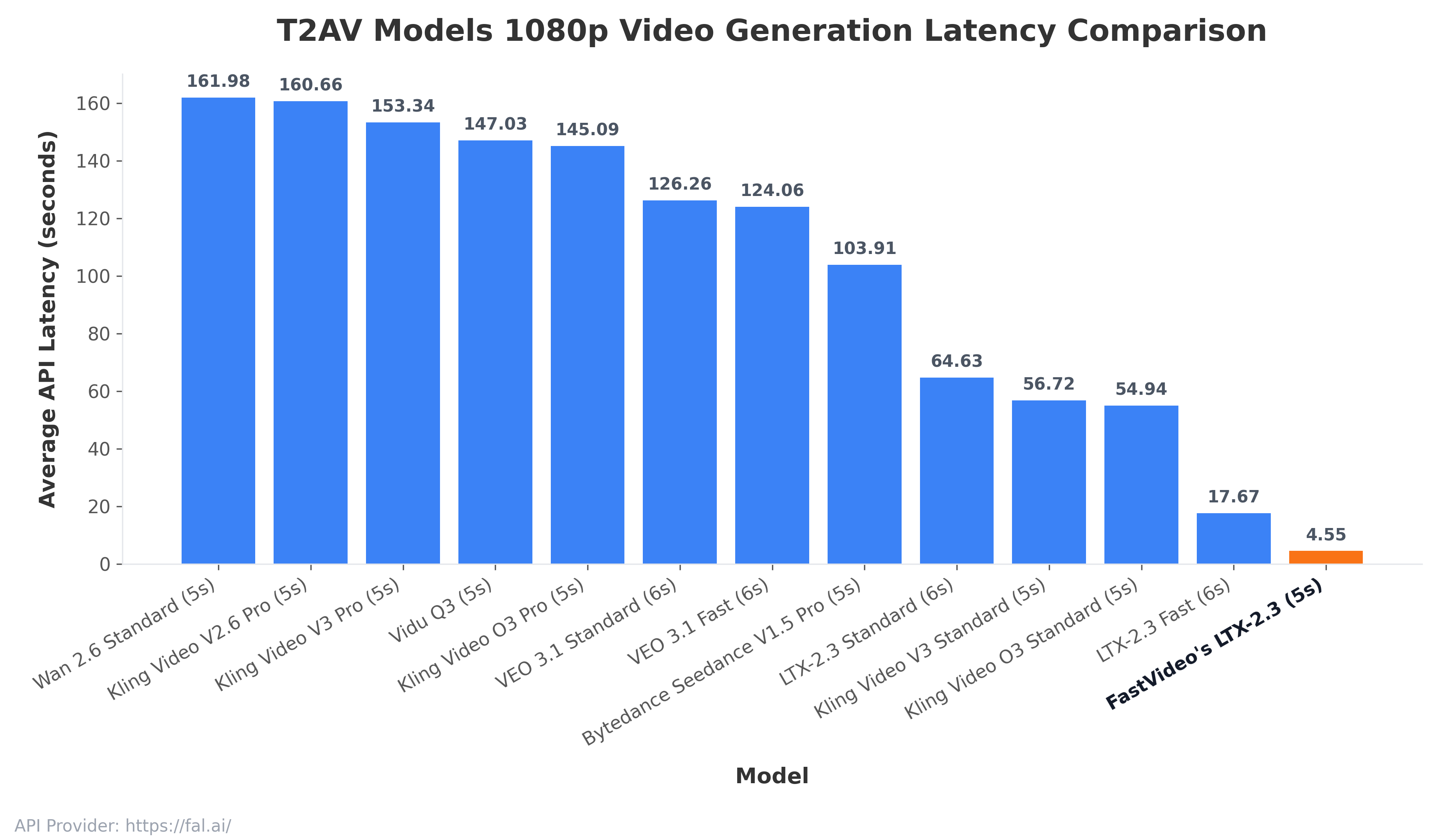
In this post, we release the fastest 1080p TI2AV pipeline ever. We show that 1080p video generation can be made interactive on a single NVIDIA B200 GPU with FastVideo. By combining full-stack optimization techniques, we reduced end-to-end latency by 3.9x relative to the next-fastest option.
For the first time, we achieved a ~4.55-second end-to-end latency for 5-second video generation at 1088 x 1920 resolution at 24 FPS, on a single NVIDIA B200 GPU! We believe this is an important milestone that will truly unlock the potential of creative and interactive video generation: faster feedback, lower cost, and a much more seamless creative loop.
FastVideo’s New Real-Time Inference Stack
Achieving sub-5-second end-to-end latency for 1080p generation (see figures below) requires optimization across every layer of the stack: model implementation, kernels, low-bit precision, compilation, scheduling, and even the infrastructure around frame and audio processing. Our implementation is specifically optimized for data-center grade Blackwell GPUs (B200/B300).
Fast attention for video generation. Modern video generation models are dominated by attention computation. DiTs rely on 3D spatiotemporal attention so that tokens can exchange information across both space and time. That means attention is one of the biggest consumers of FLOPs in the entire system. FastVideo incorporates optimized attention kernels for NVIDIA’s SM100/SM103 architectures, which gives us the attention engine required to keep 1080p generation interactive.
Aggressive low-precision execution with NVFP4. Another key feature of Blackwell chips is native Tensor Core support for the NVFP4 data-type. Compared to BF16, NVFP4 offers dramatically higher theoretical throughput, making low-precision execution essential if we want to fully utilize the capabilities of a B200/B300. FastVideo takes advantage of this by supporting NVFP4-quantized linear layers in the DiT while preserving output quality.
End-to-End graph and kernel optimization. We also applied aggressive graph-level and kernel-level optimization throughout the inference pipeline. Using multiple kernel fusion techniques, we optimized every major stage of the FastVideo inference pipeline: prompt encoding, latent preparation, denoising, and decoding. This matters because real latency is not merely the model’s core diffusion denoising loop, but everything around it too. FastVideo treats the entire path as a first-class systems problem.
System-Level efficiency beyond the model. To push end-to-end latency below 5 seconds, optimizing the model alone is insufficient; overhead from processing high-resolution video must also be reduced. Leveraging FastVideo’s comprehensive system profiling support, we identified IPC overhead and streamlined the surrounding I/O pipeline for frame and audio processing and storage. This includes using an optimized ffmpeg build for the target CPU so that media handling does not become a hidden bottleneck.
Serving Optimizations
The demo is served on half of a GB200 NVL72 (36x GPUs), with each GPU acting as a serving replica with load balancing. We also deploy Rust-based middleware for better serving efficiency. Due to capacity limits, we allow each user to interact for a limited amount of time. If you are interested in dedicated serving capacity or an endpoint, sign up for our waitlist.
Outlook and Conclusion
Running high-quality 1080p video generation on a single GPU dramatically simplifies deployment. It eliminates the need for heavyweight techniques such as sequence parallelism or other multi-GPU serving strategies, which are often required for fast inference in video generation. That means lower operational complexity, simpler scaling, and a much cleaner path from research to production.
For creators, it means something even more important: faster iteration. You can test more ideas in less time, keep momentum in the creative loop, and actually use video generation as an interactive tool rather than a slow batch job. For products, it opens the door to entirely new classes of applications in media generation, including rapid creative ideation, interactive storytelling tools, and future on-device and local-generation workflows.
And with continued advances in hardware and models, we believe sub-5-second local generation on consumer devices is coming sooner than most people expect. We actively working on this. Stay tuned!
About FastVideo
FastVideo is our unified framework for video diffusion post-training and inference. We build the systems layer that turns cutting-edge generative media models into fast, deployable, real-world products. It powers the diffusion backend in open ecosystems, including SGLang and Dynamo, and techniques developed in FastVideo have been adopted by top frontier labs to train media-generation models.
If you are excited about the future of fast, interactive generative video, please check out the FastVideo repo. We will also be at NVIDIA GTC 2026, so keep an eye out for us and come say hi!
Acknowledgement
We thank NVIDIA and Coreweave for supporting our development, and Lightricks for creating and open-sourcing LTX-2.3 to the community. We are also excited to co-announce that NVIDIA’s Dynamo recently added support for FastVideo as a backend. Stay tuned for more developments as this collaboration continues!
The Team
Core contributors: Matthew Noto*, Yechen Xu*, Junda Su*, Will Lin* (* equal contribution)
Contributors: Shao Duan, Kevin Lin, Minshen Zhang, Wei Zhou
Tech leads: Will Lin, Peiyuan Zhang, Hao Zhang
Advisors: Hao Zhang (corresponding), Danyang Zhuo, Eric Xing, Zhengzhong Liu