
TL;DR: 5 seconds of video. 1.8 seconds of generation. One RTX 5090. FastVideo introduces FastWan-QAD, a family of video generation models trained with a new recipe we term Quantization-Aware Distillation (QAD). Powered by FastVideo, we push a single RTX 5090 to its absolute limit: generating a 5-second 480P video in 1.8s end-to-end, outperforming both TurboDiffusion and LightX2V. Our flagship model targets native NVFP4 for the RTX 5090. We are concurrently releasing a second model utilizing FP8 linear layers to extend support to the RTX 4090 architecture.
What We Are Releasing
We are excited to release three distilled checkpoints of Wan2.1-T2V-1.3B, alongside our full QAD training recipe and inference code:
- FastWan-QAD-1.3B: Designed for NVIDIA GPUs with native NVFP4 tensor cores. It combines NVFP4 linear layers with our modified SageAttention3 FP4 backend, achieving an incredible 1.8 seconds end-to-end for a 5-second 480p video.
- FastWan-QAD-1.3B-SA2: Also utilizing NVFP4 linear layers, this variant integrates SageAttention2++ instead, achieving a 2 second end-to-end generation for a 5-second 480p video while achieving higher quality than the SageAttention3 variant.
- FastWan-QAD-FP8-1.3B: Built for previous-generation GPUs lacking FP4 tensor cores, specifically the RTX 4090. It swaps in FP8 linear layers alongside SageAttention2++, trained using the exact same QAD recipe as the Blackwell models.
All resources, including weights and scripts, are released under the Apache-2.0 license.
| Model Name | Checkpoint | Target Hardware | Precision (Linear + Attn) | Tier |
|---|---|---|---|---|
FastWan-QAD-1.3B | Huggingface Model | RTX 5090 | FP4 + FP4 | Flagship: minimal latency via native NVFP4, 1.8s for a 5s 480p video. |
FastWan-QAD-1.3B-SA2 | Huggingface Model | RTX 5090 | FP4 + FP8 | Alternative: sharpest video quality at minimal latency cost, 2.01s for a 5s 480p video. |
FastWan-QAD-FP8-1.3B | Huggingface Model | RTX 4090 | FP8 + FP8 | Compatibility: full 8-bit pipeline fallback, 3.4s for a 5s 480p video. |
The Inference Stack
We achieve our excellent performance by attacking every layer of the stack: precision, attention, kernel fusion, compilation, and decoding. To maximize video quality, we avoid sparse routing entirely and keep attention 100% dense, scaling the pipeline down to aggressive low-bit precisions across the three hardware-targeted configurations above.
Quantize Everything. Every major linear layer in the DiT is quantized to its hardware-specific low-bit representation (NVFP4 or FP8), with activations quantized on the fly. We match the linear precision with either an FP4 (SageAttention3) or FP8 (SageAttention2++) dense attention backend.
Quantization-Aware Distillation. None of these speedups matter if visual quality collapses, and naive low-bit attention (especially NVFP4) visibly degrades video. We recover the base model’s quality with a two-stage QAT recipe: a quantization-aware finetune that matches the target precision matrix, followed by quantization-aware DMD distillation down to just 3 sampling steps. Throughout distillation, the attention path uses fake quantization in the backward pass following our Attn-QAT method, forcing the model to adapt to low-bit attention errors during training. We also found that the best training data differs by checkpoint: FastWan-QAD-1.3B is distilled on real video data (Mixkit), while the SA2 and FP8 variants use our synthetic Wan2.1-14B data. We determined this split empirically, each configuration reaches its highest quality with the corresponding data source.
Kernel Fusion. A large fraction of wall-clock time in a small DiT is the “glue” around the matmuls: ops like LayerNorm, AdaLN modulation, residual adds, and gating. We fuse these into single kernels: one pass for the pre-attention modulated norm, and a combined gated-residual-add + norm + scale + shift for the post-attention path. This collapses what were many small memory-bound launches per block into a couple of fused ops. On top of this, the DiT, text encoder, and decoder are fully compiled to eliminate launch and Python runtime overhead.
Fast Decoding and No CFG. For decoding we swap the full Wan VAE for TAEHV, a tiny autoencoder, removing the VAE as a latency bottleneck. We run those 3 steps with CFG disabled, halving the per-step transformer cost — the final ingredient that brings the full pipeline to 1.8 seconds.
Comparison
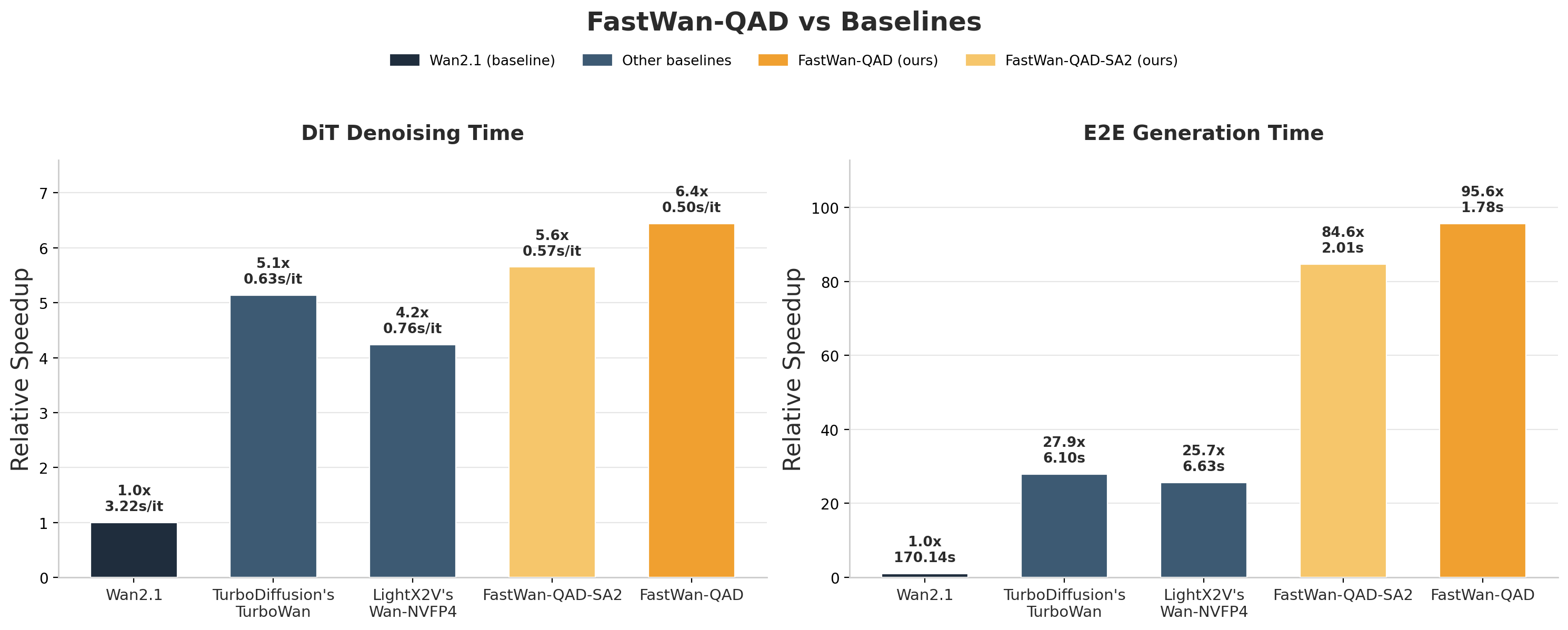
We evaluate video generation on a single RTX 5090 GPU. End-to-end times below cover the full generation pipeline.
| Method | E2E Time |
|---|---|
| Original Wan2.1-1.3B | 170s |
| TurboDiffusion | 6.10s |
| LightX2V Wan-NVFP4 | 6.91s |
| FastWan-QAD (Ours) | 1.8s |
A 4-way qualitative comparison across TurboDiffusion, LightX2V, our FP4 attention + FP4 linear model, and our FP8 attention + FP4 linear model, all generating 5-second 480p videos on a single RTX 5090.
| TurboDiffusion | LightX2V | FastWan-QAD | FastWan-QAD-SA2 |
|---|---|---|---|
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
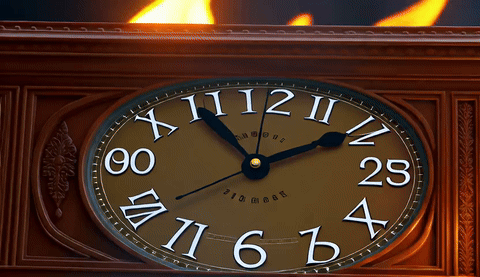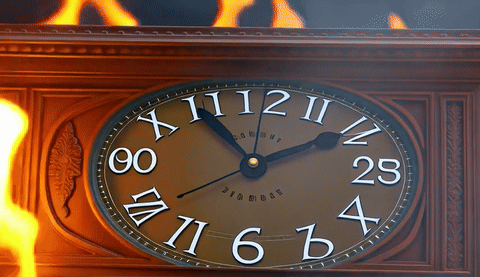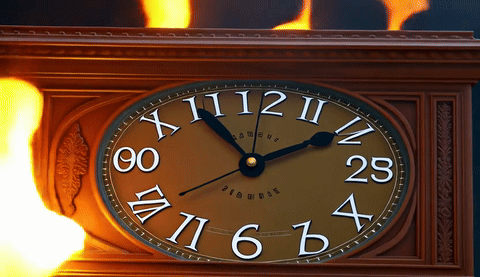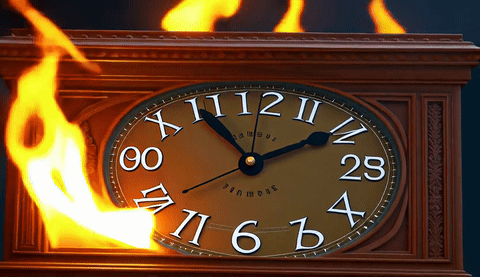 | 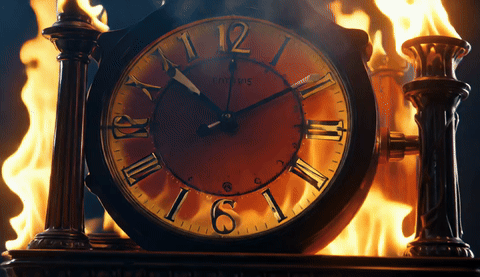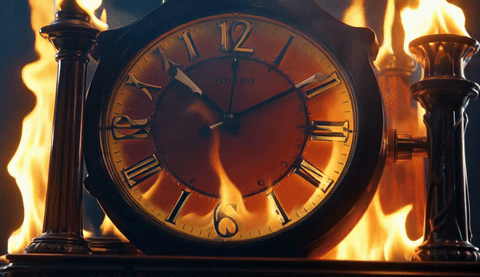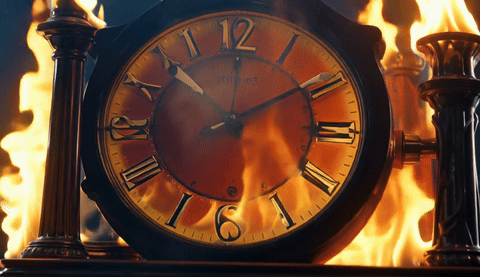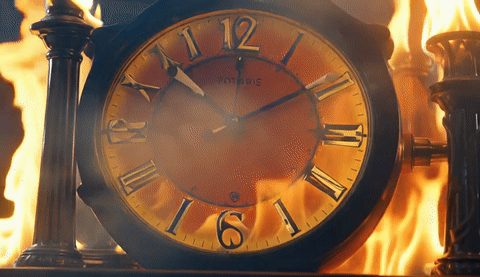 |  |  |
 |  |  |  |
 |  |  |  |
How to Run
docker run --gpus all --ipc=host --rm -it ghcr.io/hao-ai-lab/fastvideo/fastvideo-dev:py3.12-sha-f889e6b bash
# should drop you in /FastVideo with venv already activated
git fetch && git checkout main
# build fastvideo-kernel
cd fastvideo-kernels/ && ./build.sh && cd ..
git clone https://github.com/madebyollin/taehv
uv pip install ./taehv
# run generation:
FASTVIDEO_DISABLE_ATTENTION_COMPILE=0 FASTVIDEO_ATTENTION_BACKEND=ATTN_QAT_INFER python examples/inference/optimizations/FastWan_QAD_TAEHV.py --model FastVideo/FastWan-QAD-1.3B --distilled_model "" --taehv_checkpoint taehv/taew2_1.pth
Next Steps
Optimizing the 1.3B architecture is just the beginning. We are actively extending the QAD recipe to scale up to larger frontier models, including Wan2.1-14B and the NVIDIA Cosmos 2.5 / 3 families. Furthermore, we are exploring image-to-video (I2V) distillation to bring Dreamverse, our interactive vibe directing workspace, off of enterprise hardware and directly onto consumer GPUs. Stay tuned!
We welcome and value any feedback, contributions, and collaboration. If you have a feature or model request for Dreamverse, feel free to join our Slack channel or submit an issue at our repo. To contribute, please check out Contributing to FastVideo for how to get involved!
Acknowledgements
We thank NVIDIA and MBZUAI for supporting the development and release of FastWan-QAD.
FastVideo Team
Contributors: Loay Rashid*, Alex Zhang*, Kaiqin Kong*, Kevin Lin*, Matthew Noto*, Will Lin* (*equal contribution)
Tech leads: Loay Rashid, Will Lin, Hao Zhang
Advisors: Hao Zhang, Eric Xing