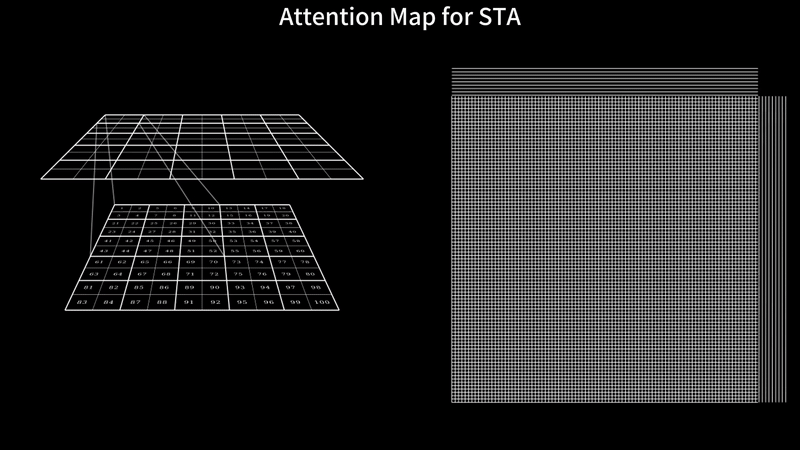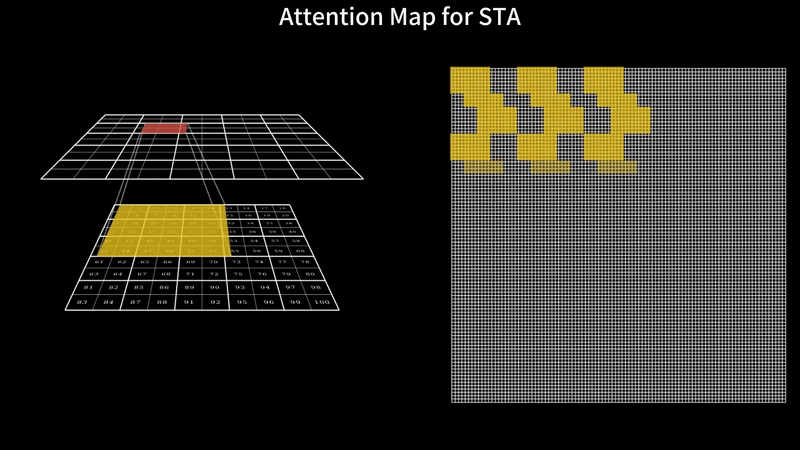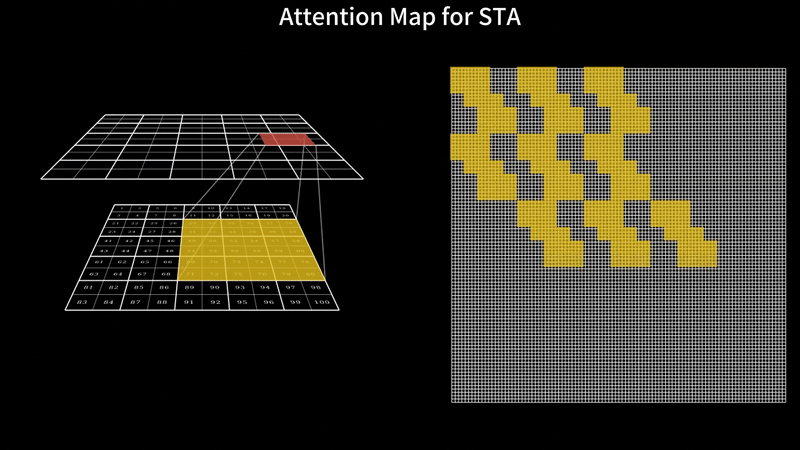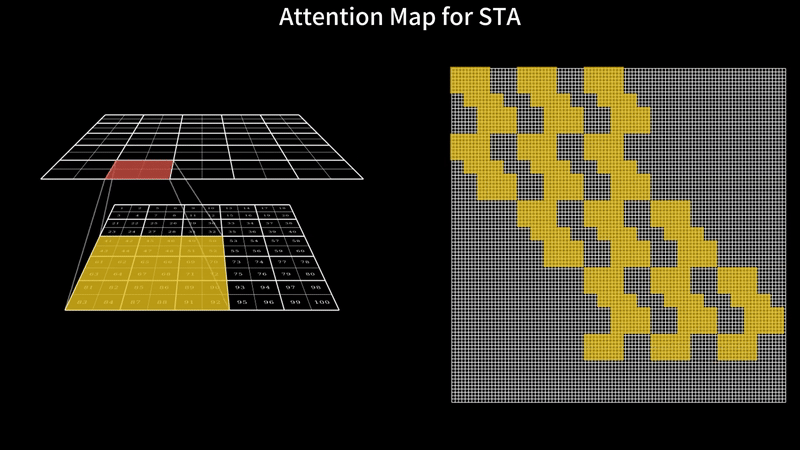
Fast Video Generation with Sliding Tile AttentionFebruary 18, 2025Peiyuan Zhang, Yongqi Chen*, Runlong Su*, Hangliang Ding, Ion Stoica, Zhengzhong Liu, Hao Zhang
Dynasor: More Efficient Chain-of-Thought Through Certainty ProbingFebruary 16, 2025Yichao Fu*, Junda Chen*, Yonghao Zhuang, Zheyu Fu, Ion Stoica, Hao Zhang
Efficient LLM Scheduling by Learning to RankJanuary 13, 2025Yichao Fu, Siqi Zhu, Runlong Su, Aurick Qiao, Ion Stoica, Hao Zhang
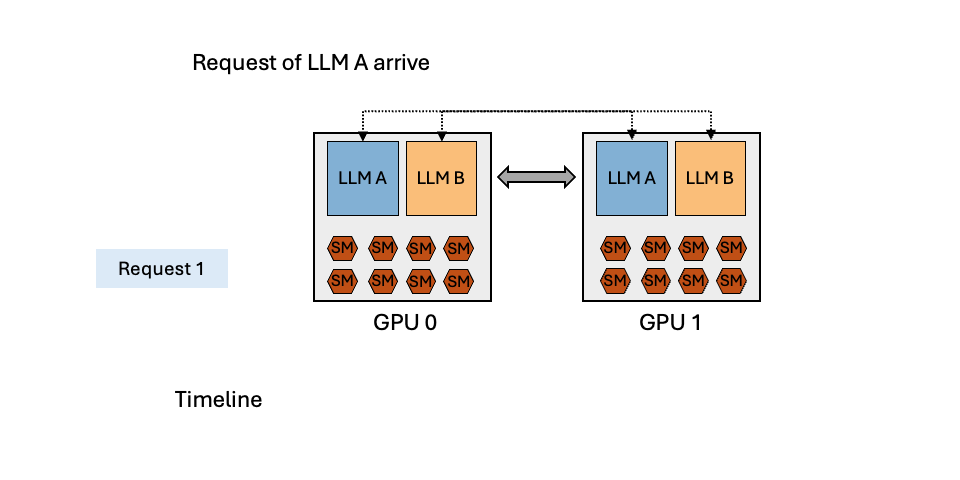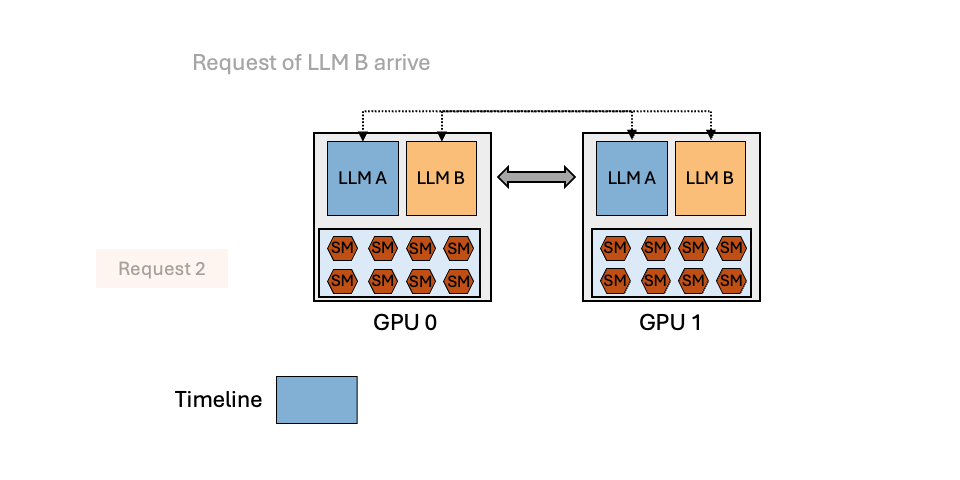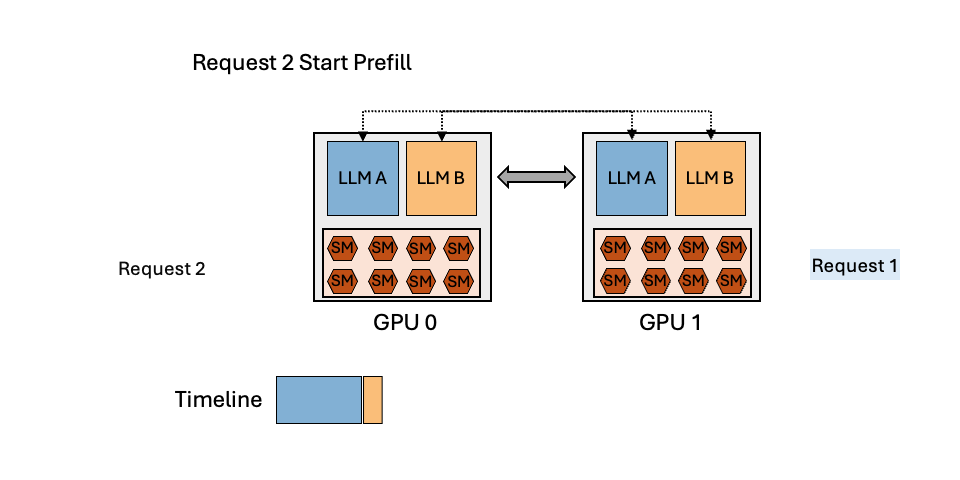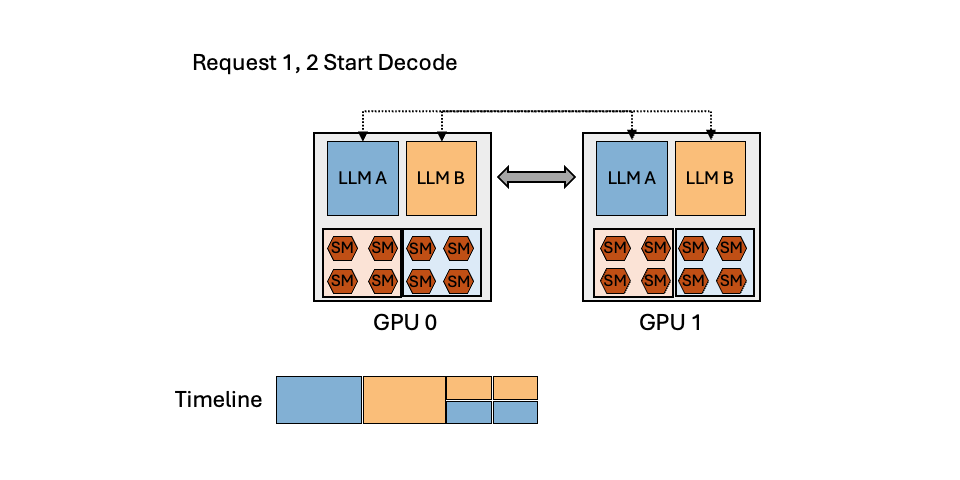
MuxServe: Flexible Spatial-Temporal Multiplexing for Multiple LLM ServingMay 20, 2024Jiangfei Duan, Runyu Lu, Haojie Duanmu, Xiuhong Li, Xingcheng Zhang, Dahua Lin, Ion Stoica, Hao Zhang
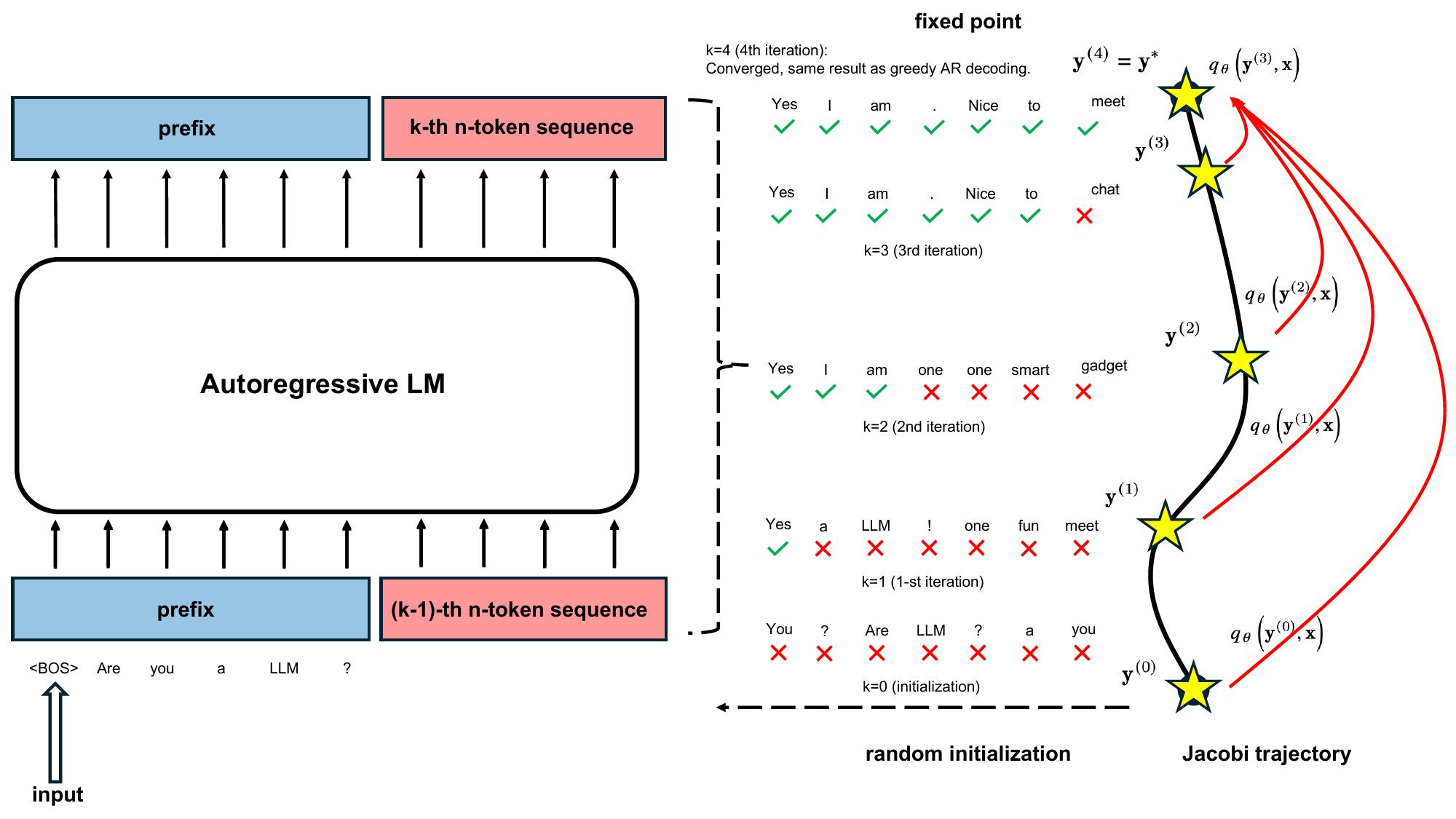
Consistency Large Language Models: A Family of Efficient Parallel DecodersMay 6, 2024Siqi Kou*, Lanxiang Hu*, Zhezhi He, Zhijie Deng, Hao Zhang
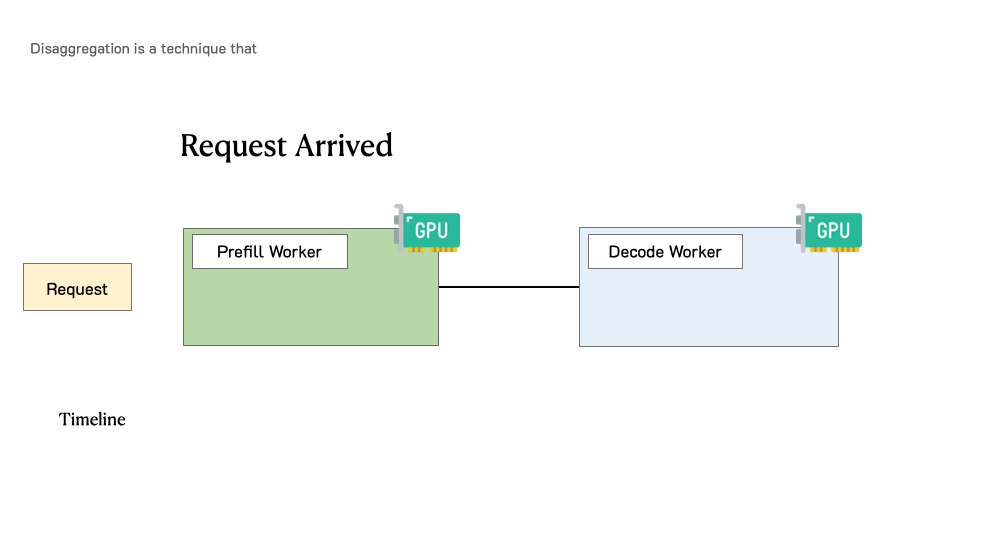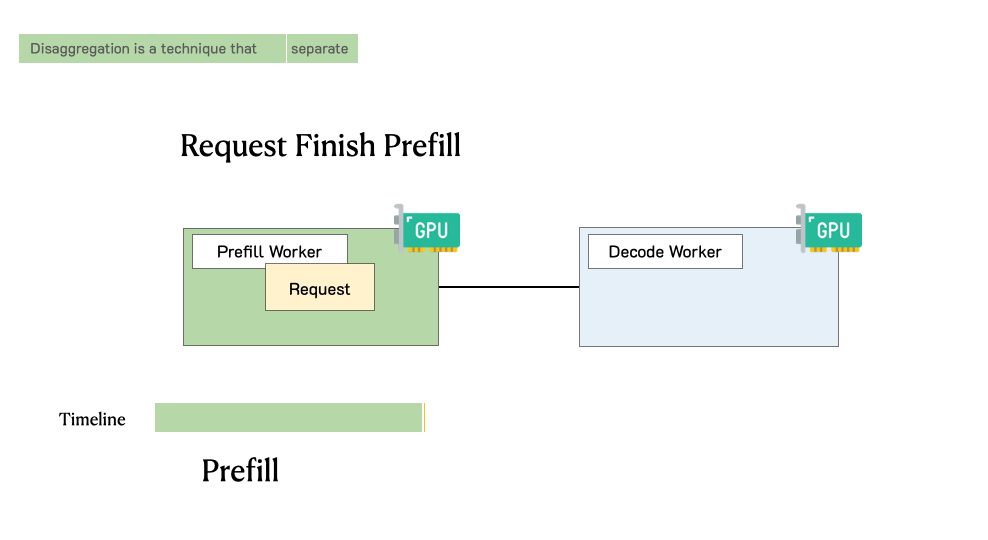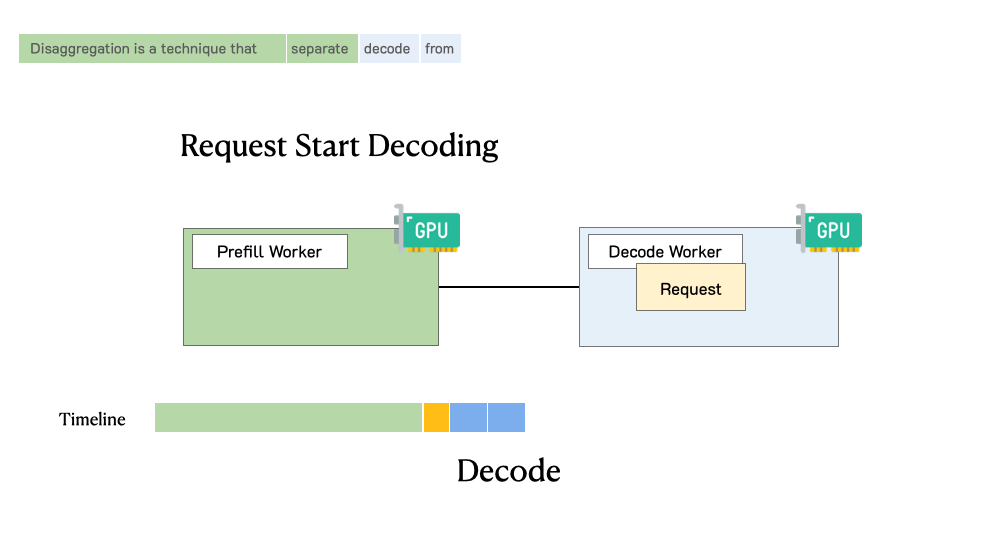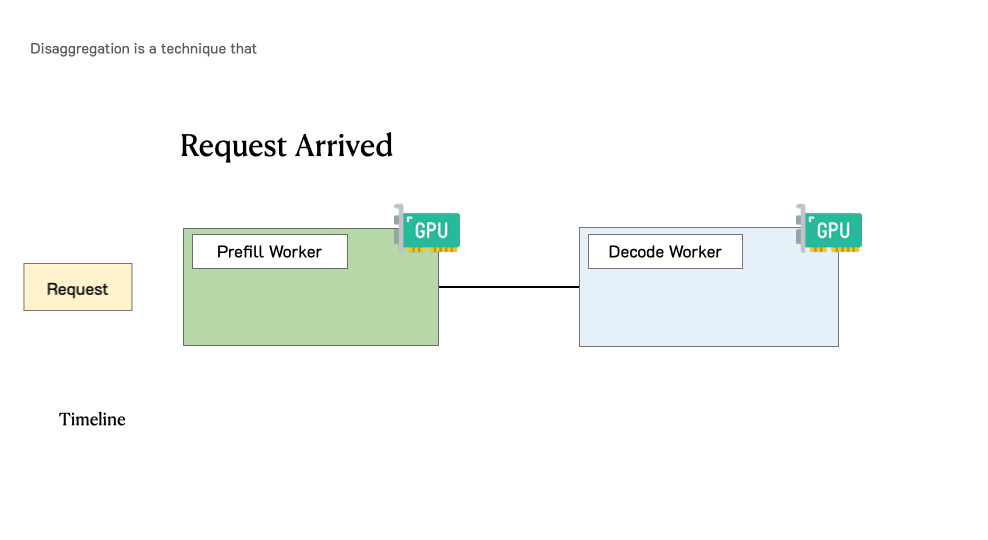
Throughput is Not All You Need: Maximizing Goodput in LLM Serving using Prefill-Decode DisaggregationMarch 17, 2024Junda Chen, Yinmin Zhong, Shengyu Liu, Yibo Zhu, Xin Jin, Hao Zhang