
TL;DR: Speculative decoding hits a scaling ceiling: a larger draft budget helps only while acceptance stays high and drafting stays cheap. Prior draft heads face a dilemma: autoregressive drafters condition on each path but pay with tree depth, while block-diffusion drafters draft in one pass but score branches independently, creating plausible yet mutually inconsistent trees. JetSpec trains a causal parallel draft head over fused hidden states from a frozen target model, so candidate-tree scores follow the target’s own autoregressive factorization. The frozen target then verifies the full tree in one forward pass, losslessly. On Qwen3-8B, greedy decoding with budget 256, JetSpec reaches 9.64x on MATH-500 and 4.58x on open-ended chat, and these gains carry into real single-stream serving on JetSpec’s own engine with an average of around 1000 TPS throughput on MATH-500 using a single B200 GPU.
Background
Modern LLM serving is still bottlenecked by autoregressive decoding: each token depends on the previous one, so generation is inherently sequential. Speculative decoding accelerates this process by drafting multiple future tokens and verifying them with the target model, but its speedup is controlled by two factors: (1) how many drafted tokens are accepted, and (2) how cheaply those tokens are drafted. Increasing the draft budget only helps when acceptance stays high and cumulative draft overhead stays low.
Existing head-based speculative decoding methods expose a core trade-off. Autoregressive draft heads such as Medusa and EAGLE-style methods preserve the target’s factorization and can produce faithful continuations, but drafting grows with tree depth. Parallel block-diffusion heads can draft a whole block in one pass, but positions are scored independently, so deeper branches can drift away from what the target would actually generate. Retrieval-based drafters avoid learned heads, but depend on lexical overlap or repeated text.
| Method | Drafting Style | Causal Draft Path | Tree Quality | Draft Cost | Speedup |
|---|---|---|---|---|---|
| AR baseline | None | N/A | N/A | N/A | 1x |
| AR draft heads | multiple-pass sequential | ✅ | 😃 | 💰💰💰 | 3~4x |
| Block-diffusion heads | one-pass block draft | ❌ | 😐 | 💰 | 3~6x |
| JetSpec | one-pass causal tree draft | ✅ | 😃 | 💰 | 4~10x |
This leads to the central question behind JetSpec: can we draft an entire speculative tree in one parallel pass while still scoring branches according to the target model’s causal, autoregressive factorization? JetSpec answers yes by combining causal parallel tree drafting with one-pass verification by the frozen target model.
At a high level, JetSpec targets both sides of the speculative-decoding bottleneck:
- Low drafting cost: generate many tree nodes in one draft-head forward pass.
- High acceptance: condition every node on its branch prefix, not just on its absolute future position.
- Lossless verification: let the frozen target verify the tree and commit only the prefix it agrees with.
JetSpec
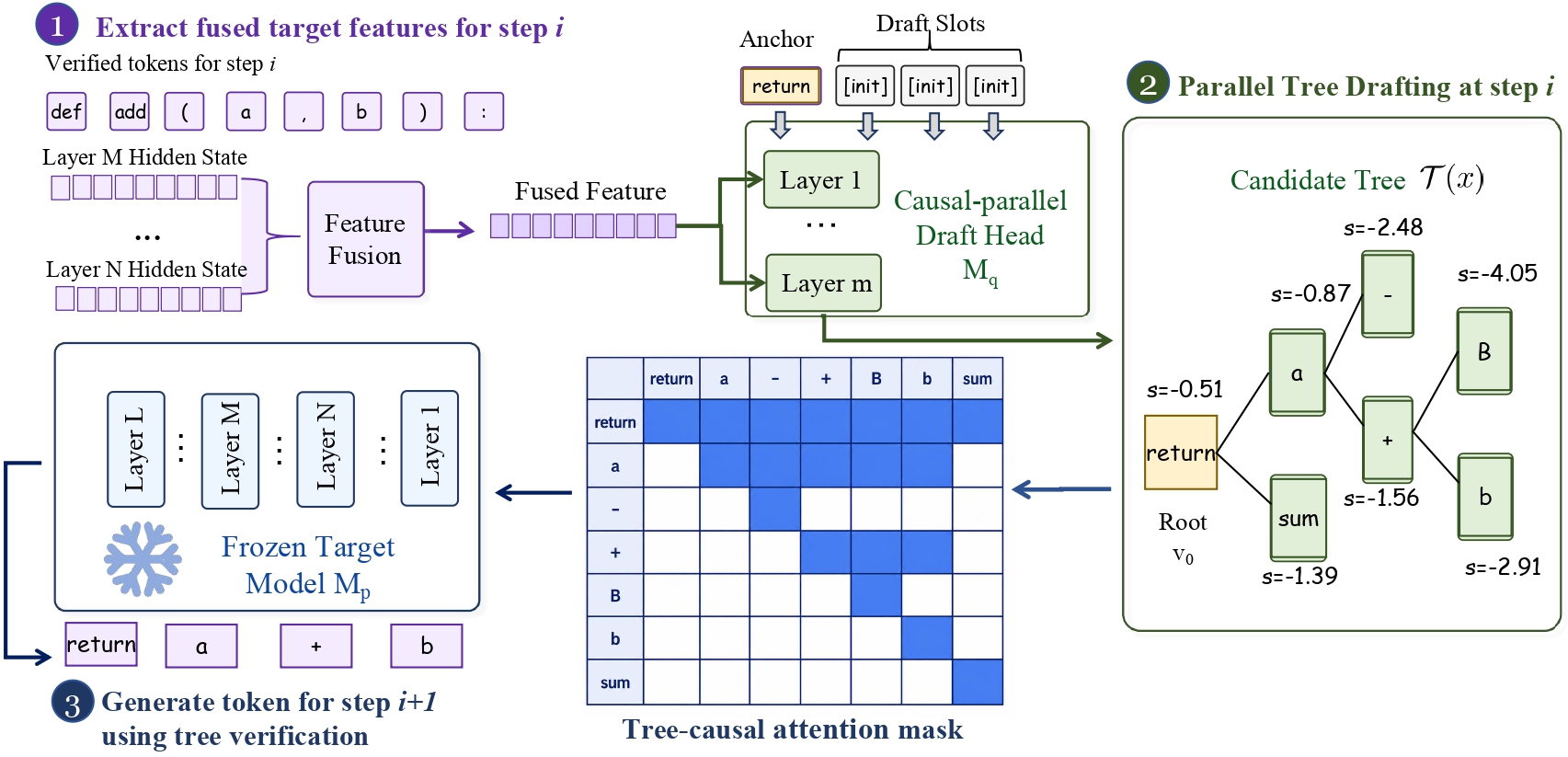
JetSpec trains a lightweight causal parallel draft head on top of a frozen target LLM. The head reuses rich multi-layer hidden features from the target, so drafting remains cheap, but it applies a tree-causal attention mask across draft slots. Each tree node can attend to the original prefix and its own ancestors, but not to unrelated sibling branches or descendants. As a result, all nodes are computed in parallel while every branch still follows an autoregressive-like dependency structure.
At inference time, the frozen target verifies every node in the speculative tree in a single forward pass under a tree-causal attention mask. The acceptance rule follows speculative decoding and commits the longest prefix accepted, so JetSpec preserves the target model’s exact output distribution under the same sampling rule. In other words, JetSpec improves speed without changing what the target would generate.
Training the Head
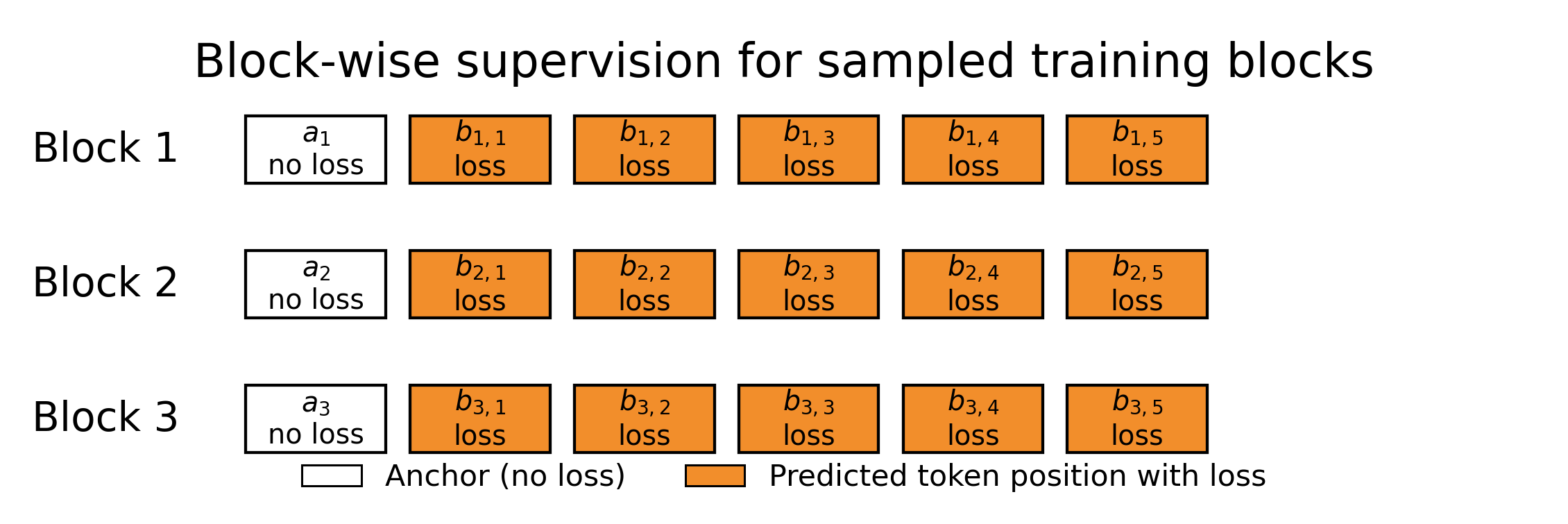
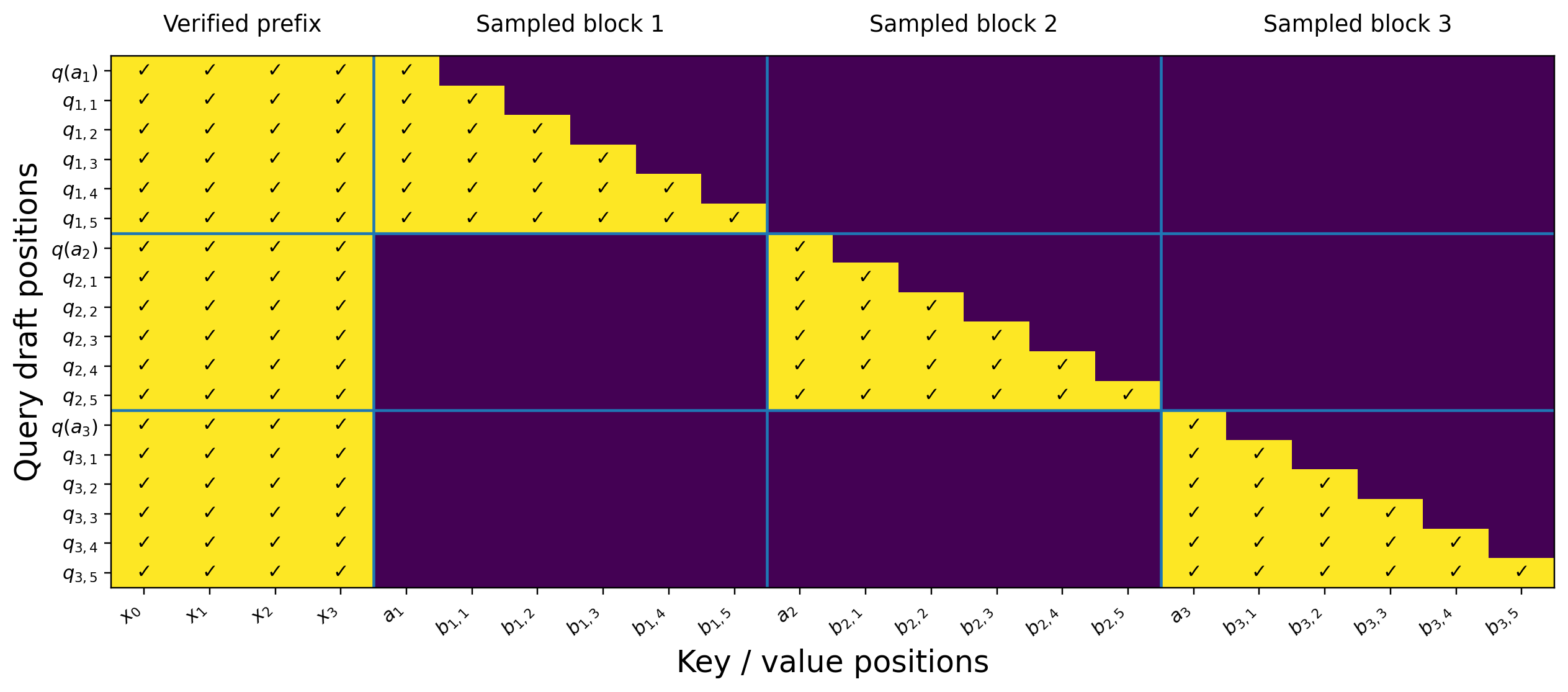
Only the draft head is trained; the target model stays frozen. This lets JetSpec attach to a production model without changing its weights. Training samples anchor positions in target-aligned sequences, builds future-token blocks, and supervises the head against the target’s own next-token distributions.
We train with a causal mask over selected anchor positions, with each anchor expanded into a 16-token draft block. Each draft position attends to preceding positions within its block, enabling a single parallel pass to produce an internally consistent draft tree. In ablations, forward-KL style distillation slightly outperfroms SFT and is preferred because it preserves probability mass over multiple plausible continuations, while mode-seeking reverse-KL is less suitable for budgeted tree drafting.
Tree Drafting and Verification
Both JetSpec and diffusion-style draft heads can spend the same draft budget; the difference is the quality of the tree that budget buys. A block-diffusion head produces all positions from one shared hidden state with no causal mask between depths, so a depth-2 distribution may never condition on the token chosen at depth 1. When two independently likely tokens cannot follow each other, the surrogate can still promote their composition to the top of the tree. JetSpec’s causal mask anchors each position to its branch prefix, so the verifier sees branches the target is more likely to accept.
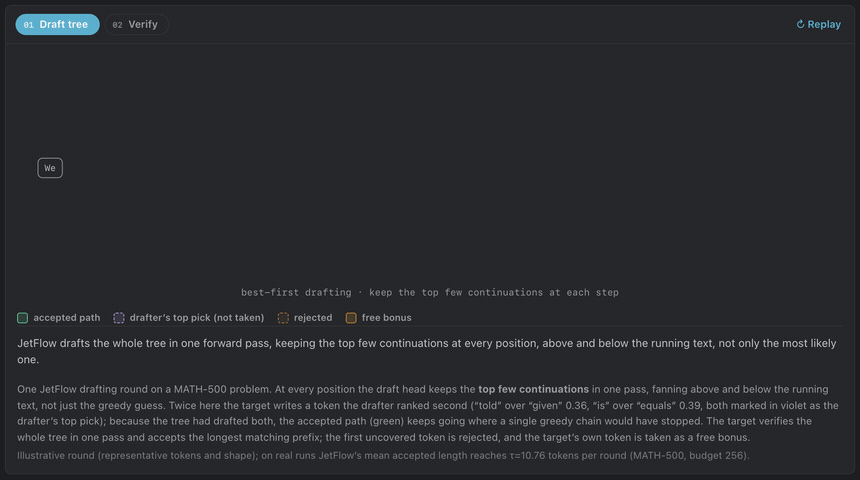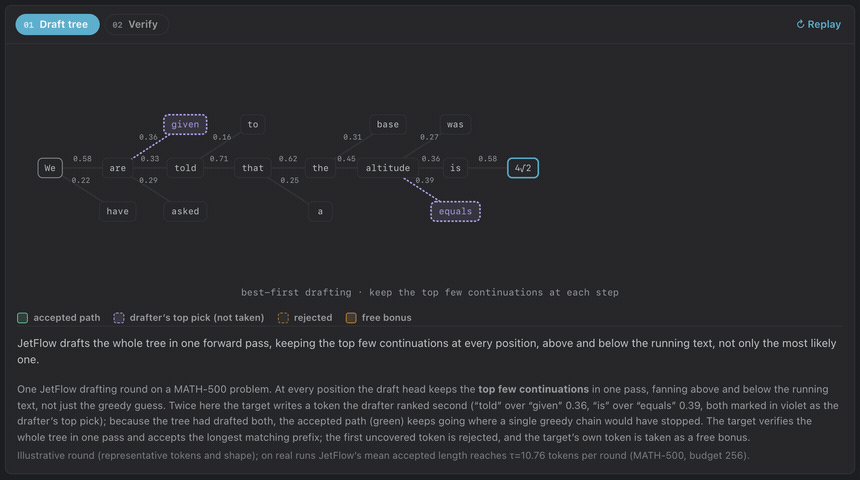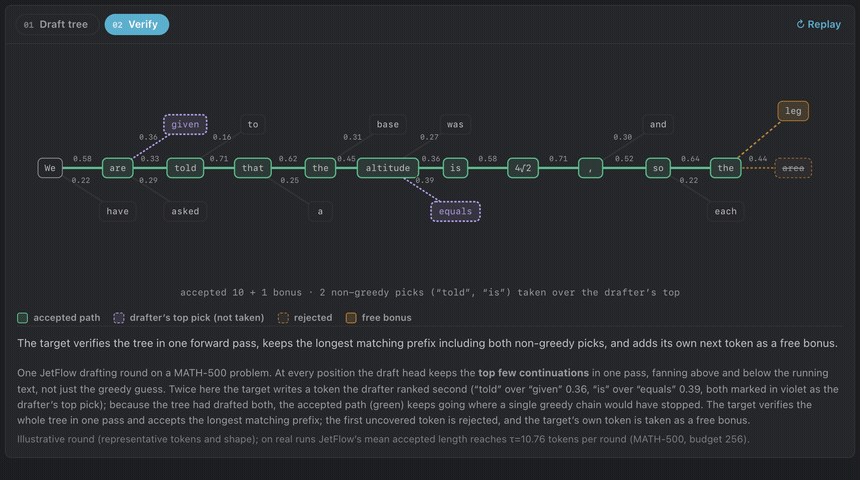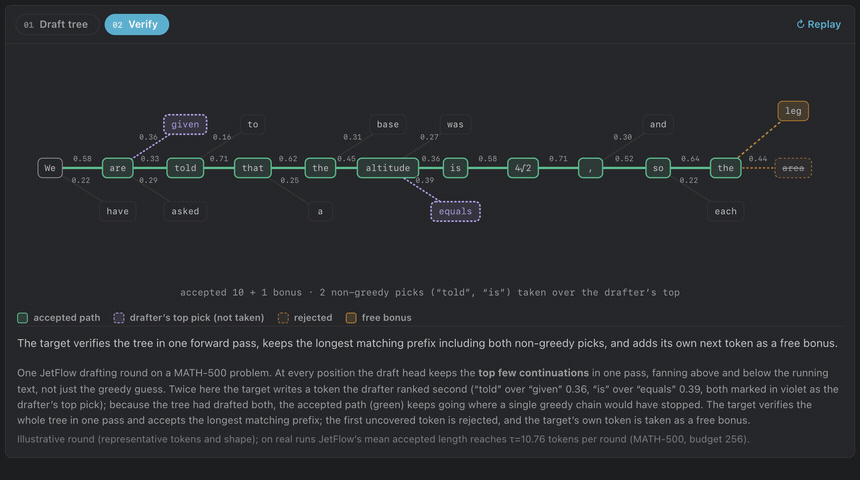
Experiments
Results
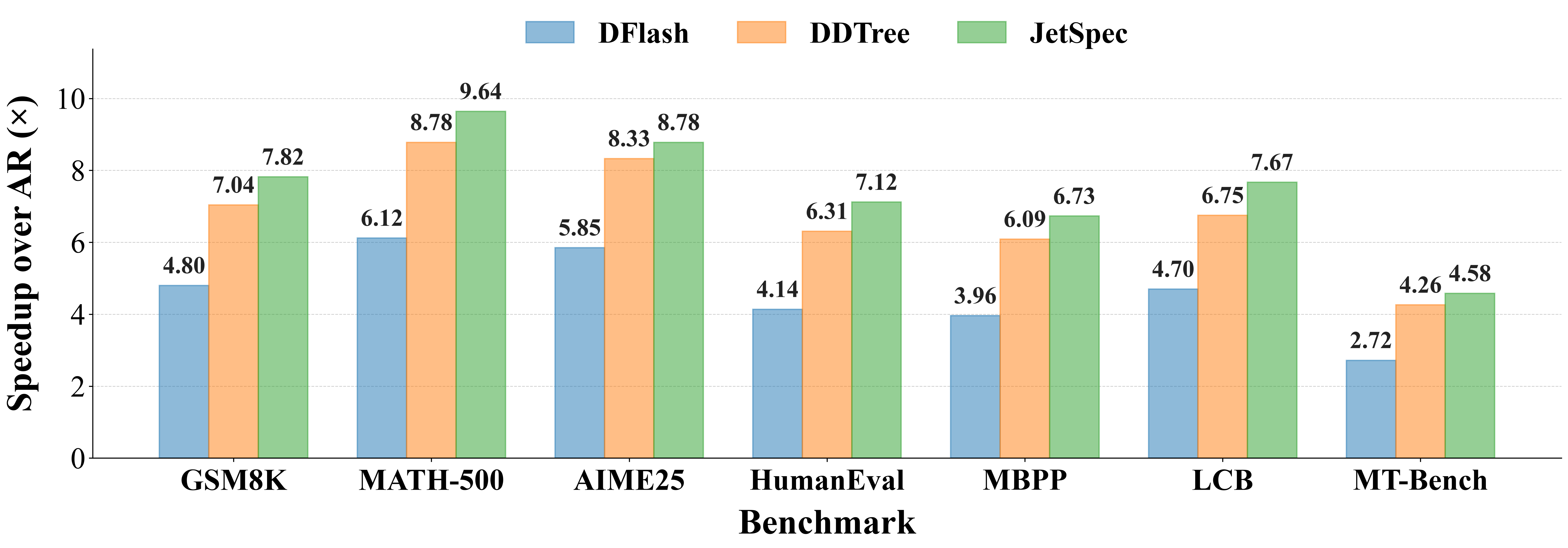
JetSpec is evaluated on math, coding, and open-ended chat benchmarks with Qwen3-8B and Qwen3-30B-A3B under both greedy and sampling settings. The headline pattern is budget scaling: as the draft budget grows, JetSpec keeps converting extra candidate nodes into longer accepted prefixes, while prior heads saturate earlier.
At high token budget regime (>64 tokens), JetSpec leads DDTree (a tree-based variant of DFlash, our implementation follows this paper) and DFlash on every benchmark. The full grid below reports end-to-end speedup (Spd) and mean accepted length (τ) on Qwen3-8B over a selection of tasks.
| Method | Budget | MATH-500 Spd (τ) | AIME25 Spd (τ) | HumanEval Spd (τ) | MBPP Spd (τ) | LCB Spd (τ) | MT-Bench Spd (τ) |
|---|---|---|---|---|---|---|---|
| EAGLE-3 | 64 | 2.36 (4.13) | 2.35 (4.04) | 2.49 (4.26) | 2.22 (3.81) | 2.09 (3.62) | 2.19 (3.88) |
| DDTree | 64 | 6.51 (7.16) | 6.40 (6.96) | 5.08 (5.57) | 4.99 (5.49) | 5.47 (6.06) | 3.74 (4.51) |
| DDTree | 128 | 8.27 (9.19) | 7.93 (8.66) | 5.93 (6.52) | 5.70 (6.28) | 6.42 (7.25) | 4.12 (5.14) |
| DDTree | 256 | 8.78 (9.81) | 8.33 (9.24) | 6.31 (6.96) | 6.09 (6.70) | 6.75 (7.72) | 4.26 (5.41) |
| JetSpec | 64 | 6.76 (7.42) | 6.47 (7.00) | 5.53 (6.06) | 5.34 (5.88) | 5.95 (6.59) | 3.97 (4.77) |
| JetSpec | 128 | 8.93 (9.95) | 8.26 (9.10) | 6.66 (7.28) | 6.31 (6.95) | 7.29 (8.21) | 4.37 (5.52) |
| JetSpec | 256 | 9.64 (10.76) | 8.78 (9.82) | 7.12 (7.78) | 6.73 (7.43) | 7.67 (8.79) | 4.58 (5.94) |
Takeaways:
- Generalizability: largest gains appear on reasoning-heavy math and coding tasks, in consistent with our training data choice. JetSpec also generalizes with >4x speedup on open-ended conversational tasks.
- Non-greedy sampling: gains shrink but remain consistent, showing the causal-tree benefit is not limited to deterministic decoding.
- Budget scaling: larger tree budgets help JetSpec more reliably because the draft tree stays branch-conditioned.
Training with and without Causality
Bidirectional diffusion heads can recover some branch quality by training with an exponential loss weighting (an exponential loss weighting factor γ is applied in a causal order from left to right), but only near a tuned setting: they peak at a single weighting and collapse at extremes. JetSpec’s causal head holds strong speedups across the whole range and does not require this tuning.
| MATH-500 speedup by loss weighting | γ=0 | γ=3 | γ=7 | γ=15 |
|---|---|---|---|---|
| Causal (JetSpec) | 8.29 | 8.50 | 8.40 | 8.41 |
| Diffusion head | 5.46 | 8.16 | 8.36 | 6.17 |
Causality and Tree Quality
In this experiment we compare tree quality with and without causality enforced. The gap is measured the drafter’s log-probability difference, in nats (natural-log units), between its top-ranked branch and the target’s preferred continuation. A small gap means the tree contains the branch the target is more likely to accept and therefore a higher quality. On MATH-500, without loss weighting the block-diffusion head is miscalibrated, accepting a mean 4.84 tokens per round against the causal head’s 9.46.
| Rank-1 branch faithfulness, 50 MATH-500 prompts, no loss weighting | Causal | Diffusion |
|---|---|---|
| Faithful rank-1, <+5 nats | 42% | 6% |
| Extreme gap, ≥+80 nats | 0% | 26% |
| Mean accepted length | 9.46 | 4.84 |
Limitations
While the speedups reported are end-to-end and lossless, they depend on GPU compute, memory bandwidth, batching, and the chosen tree budget. In addition to the algorithm knobs and hardware specifications, wall-clock serving speedups run below pure algorithmic accepted-length ratios because real serving includes kernel-launch, KV cache management, scheduling and other host-side overhead. The best draft budget is a trade-off: a larger tree raises accepted length but also increases per-round verification cost, so the optimal point depends on the model and hardware.
JetSpec Serving Optimization and vLLM Integration
To provide an inference path for real serving rather than only offline algorithmic evaluation, JetSpec includes a serving implementation based on our vLLM fork with JetSpec support and organizes draft candidates as a speculative tree, stores parent indices along with node depths, and passes this metadata into target verification. The target then verifies all speculative nodes in one forward pass under a tree-attention mask, and the acceptance rule remains lossless by construction.
We further implement paged FlashAttention kernels in both Triton and NVIDIA CuTe DSL that apply the tree mask directly inside the attention computation, without materializing a dense per-request mask. Larger budgets reduce verification rounds at low to moderate load, but can become less efficient under heavier batching because each round carries more verification and memory pressure.
Get Started
For more details, please see the JetSpec paper and codebase:
- Paper: https://arxiv.org/pdf/2606.18394
- Website and Demos: https://jetspec-project.github.io/jetspec-web/
- GitHub: https://github.com/hao-ai-lab/JetSpec
- Model Zoo: https://huggingface.co/JetSpec
Because JetSpec keeps the target model frozen and verifies under a lossless acceptance rule (speculative decoding), with a plug-and-play causal parallel drafting head, it can be attached to an existing model as a speculative decoding path while preserving the target output distribution.
Citation
@misc{hu2026jetspec,
title = {JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting},
author = {Hu, Lanxiang and Feng, Zhaoxiang and Wu, Yulun and Yuan, Haoran and Zhao, Yujie and
Qian, Yu-Yang and Wang, Bojun and Zhao, Peng and Jiang, Daxin and Zhu, Yibo and Rosing, Tajana and Zhang, Hao},
year = {2026},
eprint = {2606.18394},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/2606.18394}
}