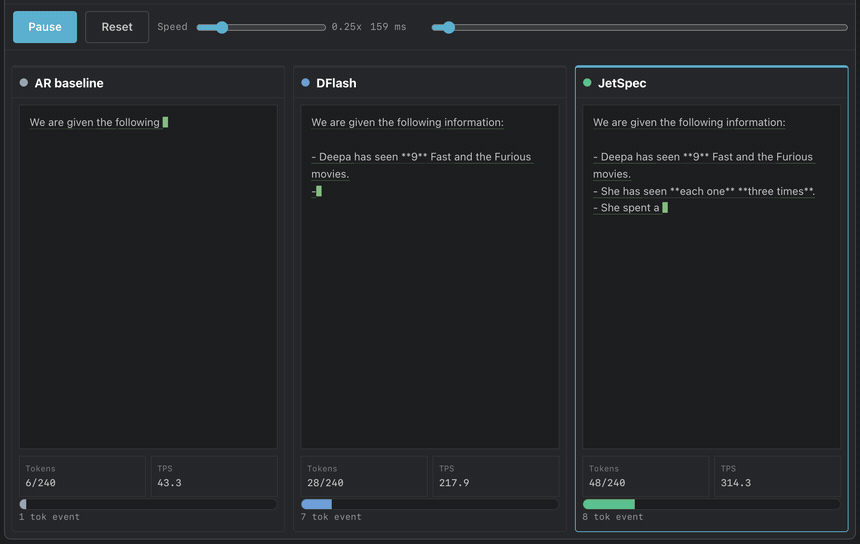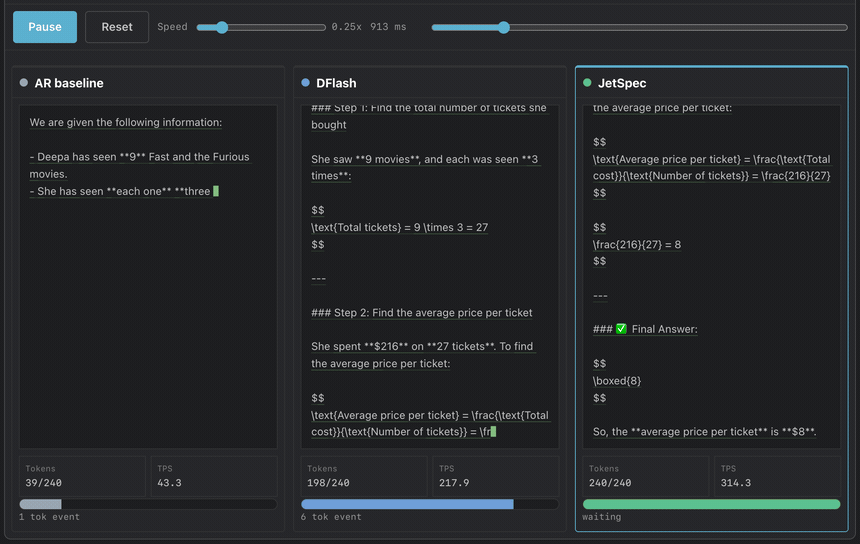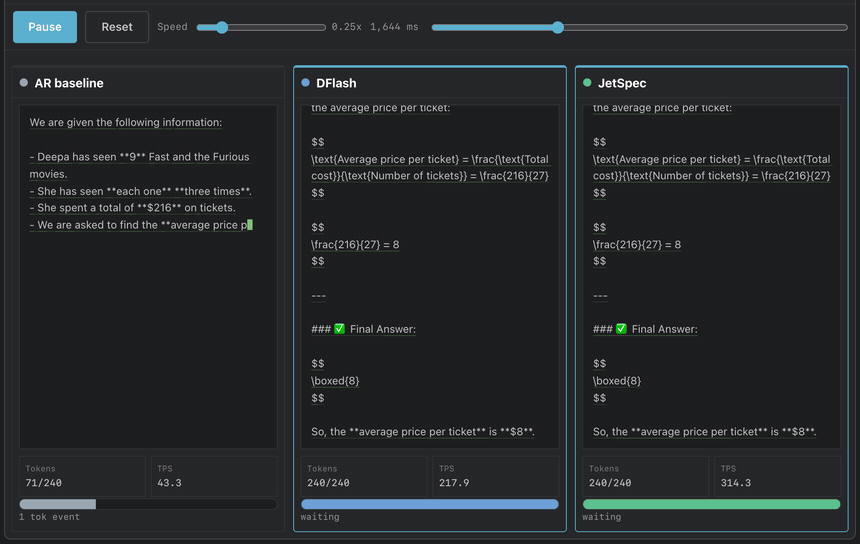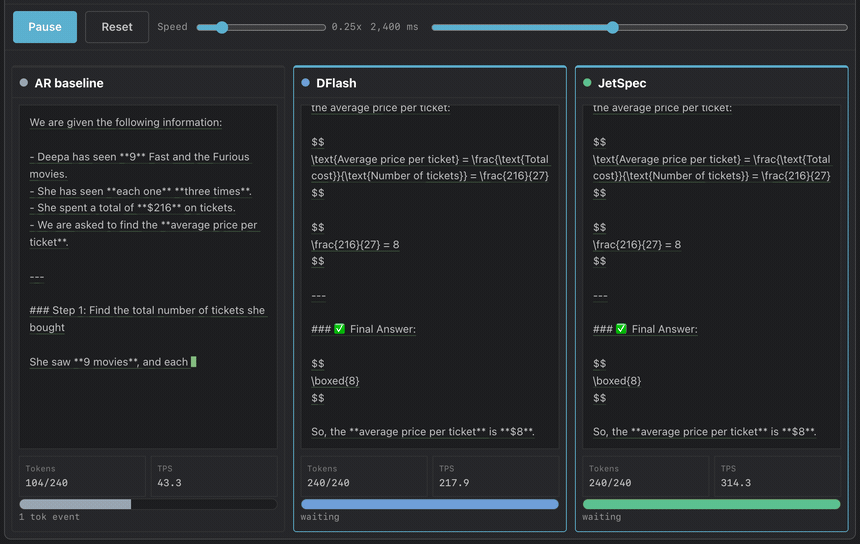

TL;DR: Speculative decoding hits a scaling ceiling: a larger draft budget helps only while acceptance stays high and drafting stays cheap. Prior draft heads face a dilemma: autoregressive drafters condition on each path but pay with tree depth, while block-diffusion drafters draft in one pass but score branches independently, creating plausible yet mutually inconsistent trees. JetSpec trains a causal parallel draft head over fused hidden states from a frozen target model, so candidate-tree scores follow the target’s own autoregressive factorization. The frozen target then verifies the full tree in one forward pass, losslessly. On Qwen3-8B, greedy decoding with budget 256, JetSpec reaches 9.64x on MATH-500 and 4.58x on open-ended chat, and these gains carry into real single-stream serving on JetSpec’s own engine with an average of around 1000 TPS throughput on MATH-500 using a single B200 GPU.